

En mis clases de ética en la investigación y sobre integridad científica siempre hay un momento en el que observo que los alumnos se mueven inquietos en su silla y empiezan a cuchichear y comentar con los compañeros sentados a sus lados. Ocurre invariablemente, lo cual me sugiere que el tema del que hablo es más habitual y popular de lo que ya imaginaba. Y me confirma que se trata de uno de los mayores problemas que tenemos en la ciencia, que lleva inevitablemente a uno de los mayores males de la ciencia. Y sorprende por su sencillez y simpleza, por su aparente inocencia. Pero es una verdadera carga de profundidad contra el método científico.
¿A qué me estoy refiriendo? A la falta de reproducibilidad de los experimentos científicos. Los investigadores son incapaces de replicar los resultados que sus colegas han publicado. Una encuesta realizada por la revista Nature en 2016 entre 1576 investigadores concluía que más del 70% de científicos habían sido incapaces de reproducir los resultados obtenidos por otros investigadores. Y, lo que es peor, más del 50% reconocían que había sido incapaces de reproducir sus resultados, ¡los de su propio laboratorio!, al intentar replicarlos. Ante estos sorprendentes resultados, preguntados los investigadores si creían que estaban ante una crisis de reproducibilidad más de la mitad de ellos (52%) afirmaba que sí, que estábamos ante una crisis de reproducibilidad significativa. Un 38% adicional se apuntaban a calificar la crisis de reproducibilidad, que reconocían, como más ligera, menos relevante. Sumando ambas cifras nos sale que un 90% de los investigadores consultados creían que estamos, de una manera u otra, ante una crisis de reproducibilidad. Tan solo un 3% negaba la existencia de tal crisis de reproducibilidad y el 7% restante no se posicionaba al respecto. Voy a decirlo otra vez porque esto creo que es muy relevante: un 90% de investigadores cree que estamos ante una crisis de reproducibilidad.
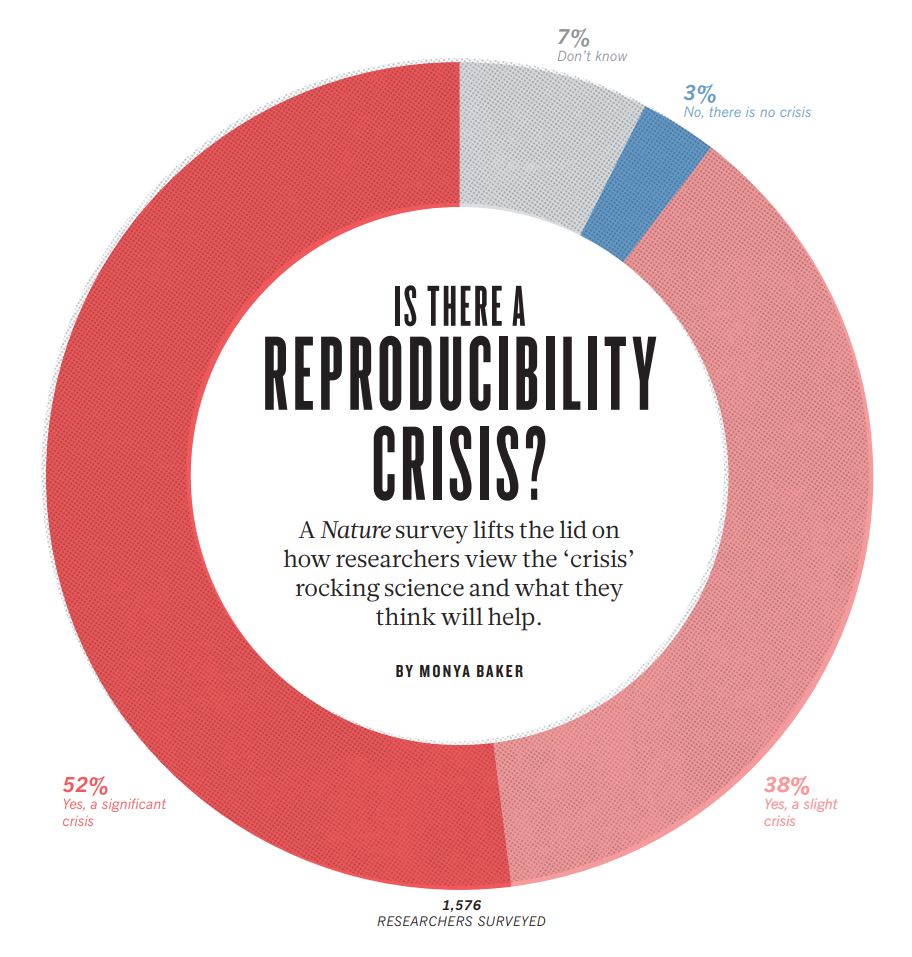
Alguien podría argumentar que esto son cosas que ocurren solamente en las disciplinas de la vida, en biología y materias relacionadas. No es así. La encuesta de Nature daba cuenta de ejemplos de falta de reproducibilidad en todas las disciplinas encuestadas, que incluían la biología, la medicina, las ciencias de la tierra y el medio ambiente, y la física y las ingenierías. En todas ellas los investigadores llegaban a conclusiones similares, con ligeras variaciones. Y la situación no ha mejorado desde entonces, pues la crisis de reproducibilidad sigue estando sobre el papel en publicaciones recientes.
¿Cuál es el origen de esta crisis de reproducibilidad? La encuesta de Nature de 2016 aportaba varias razones para ello, como por ejemplo: la presión por publicar, el reducido poder estadístico de los métodos aplicados, un número de réplicas inadecuado, una deficiente descripción de los métodos usados, falta de experiencia requerida para poder replicar el experimento, diseño experimental inadecuado, e incluso fraude, claro está. Pero de todos los factores mencionados que influían en esa falta de reproducibilidad había uno que destacaba por encima de los demás, el que era más importante: el reporte selectivo de los resultados. En otras palabras, escoger los datos que se ajustan a los resultados esperados y descartar aquellos que alejan el resultado de la hipótesis experimental. Es lo que los ingleses llaman «cherry-picking» (escoger las cerezas). Aparentemente es una intervención menor, que apenas debería causar ningún efecto, pero ¡vaya si los causa!, y lo hace de forma demasiado significativa. Veamos unos ejemplos.
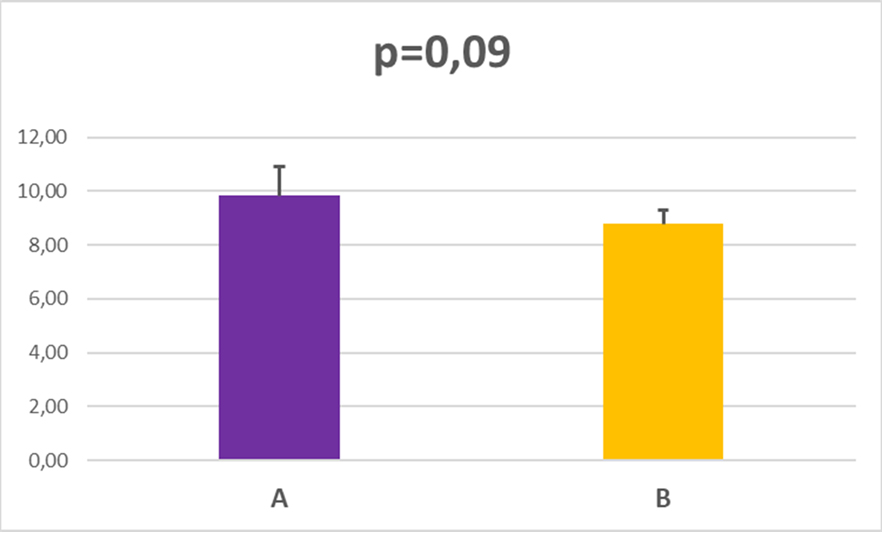
Imaginemos que queremos comparar dos series de datos experimentales, o unos datos experimentales frente a unos datos control. Es un experimento sencillo, de comparación de medias de resultados. Recogemos los datos experimentales de cada una de las dos series, calculamos los promedios y las desviaciones estándar para graficarlos y luego aplicamos un test t de Student para dos muestras suponiendo varianzas iguales (usando el test incorporado en Excel Microsoft Office 365) . La probabilidad de error que nos sale nos la indica el valor p= 0,09, que es mayor que el mínimo establecido a priori (0,05). Esto quiere decir que aceptamos la hipótesis nula (las medias son iguales). Este es un resultado negativo. Habitualmente se esperan encontrar diferencias estadísticamente significativas al comparar dos series de datos (por ejemplo concentración en plasma de una proteína en ratones control y en ratones mutantes para un determinado gen).
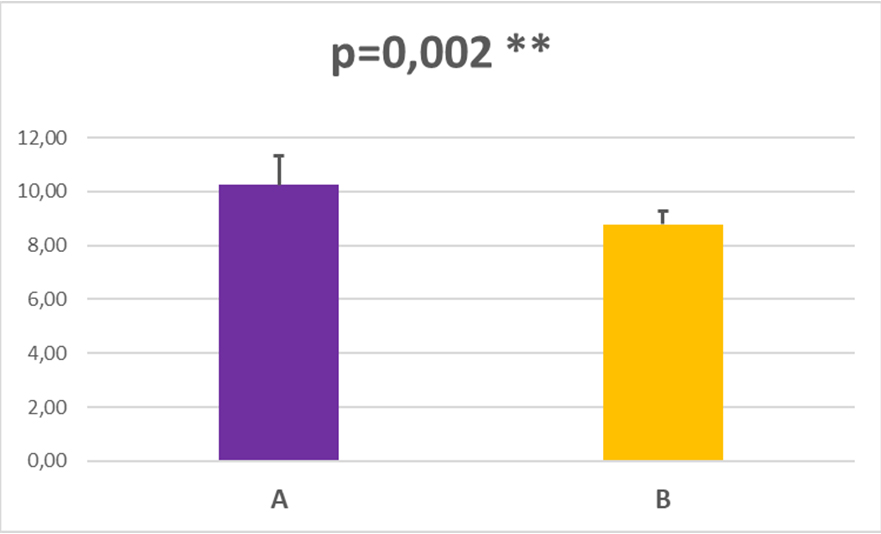
Imaginemos ahora que alguna persona del laboratorio revisa los datos experimentales y nos presenta un nuevo gráfico para comparar las medias entre los datos del grupo A y del grupo B. Y, ahora sí, en este caso al aplicar el test t-de Student para dos muestras suponiendo varianzas iguales nos sale un valor de p=0,002, que es netamente inferior al mínimo establecido previamente (0,05). Y, por lo tanto, rechazamos la hipótesis nula (las medias son diferentes) y aceptamos la hipótesis alternativa (hay diferencias estadísticamente significativas entre las dos series de datos), con una probabilidad de error muy baja, del 0,2%. Y entonces no ponemos muy contentos, porque podemos ponerle dos estrellitas (**, que quiere decir p<0,01) al gráfico que indica que hemos encontrado diferencias estadísticamente significativas. Y entonces el gráfico va de cabeza a una tesis doctoral o una publicación científica y reportamos a los cuatro vientos que sí hay diferencias entre los grupos A y B.
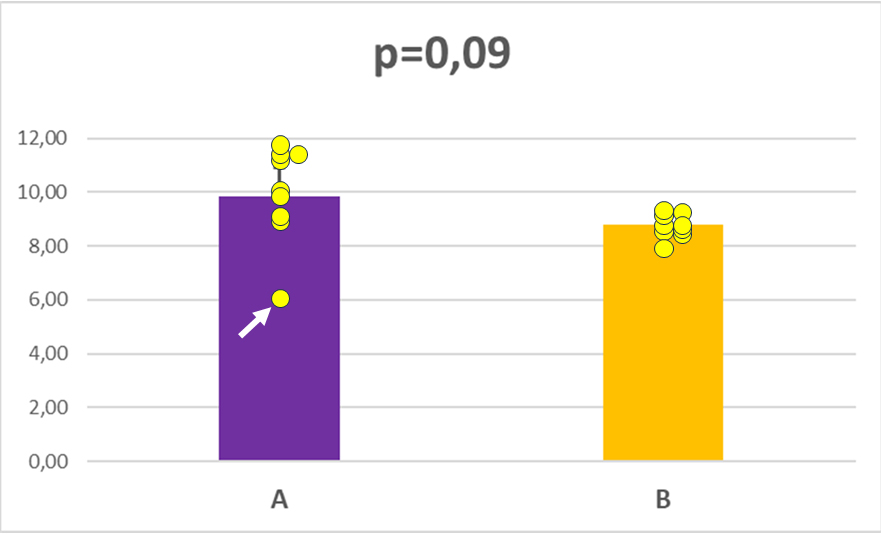
¿Por qué el primer análisis de las muestras no daba diferencias estadísticamente significativas y el segundo sí? Veamos que ha sucedido. Si añadimos los puntos individuales, los valores de datos recogidos en cada caso, y los graficamos veremos que en el grupo A hay un valor, alrededor de 6, que se aleja del resto de valores. Estos datos, que se apartan de la serie, se denominan outliers. Su natural inclusión nos hace aumentar la varianza y, consecuentemente, la desviación estándar del grupo A y, entonces, al aplicar el test t de Student para encontrar diferencias de medias vemos que el valor obtenido de p=0,09 es superior al mínimo establecido (0,05), y por eso aceptamos la hipótesis nula: no hay diferencias entre las medias.
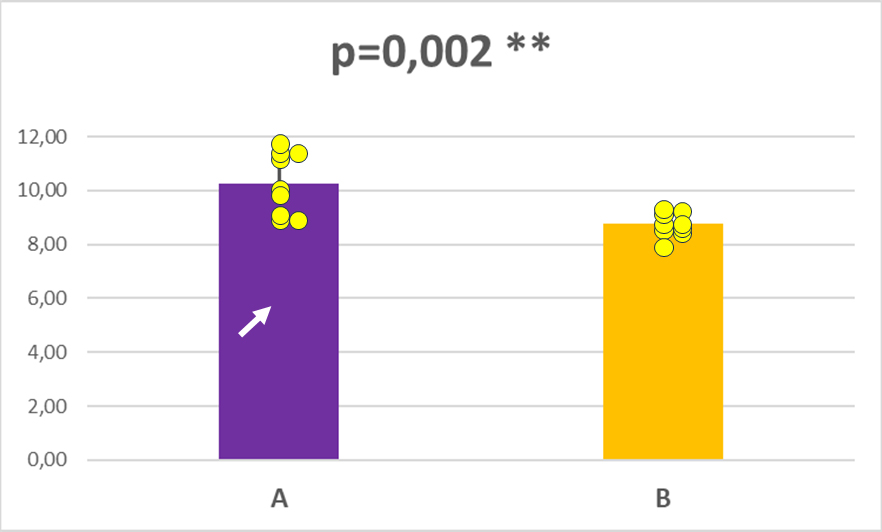
¿Qué necesitamos para convertir una ausencia de diferencias entre las medias entre unas diferencias estadísticamente significativas? Pues muy poco. Solo tenemos que «escoger las cerezas«. Nos miramos el grupo de datos individuales del grupo A y nos percatamos que uno de los puntos experimentales no parece seguir la tónica del resto, y ha salido con un valor menor. Entonces asumimos que es un valor seguramente «erróneo» y lo eliminamos del análisis. Tal cual. Y, tan pronto lo hacemos, entonces las diferencias entre los dos grupos, que antes no existían, ahora se convierten en diferencias estadísticamente significativas. Y solo hemos eliminado un dato. ¿Qué hay de malo en esto? Pues mucho. Todo. Hemos forzado el experimento, seleccionando qué datos incluíamos en el análisis y cuáles no, para que las diferencias nos salieran significativas. Cuando muy probablemente no lo son. Este valor eliminado nos estaba indicando que la variabilidad de resultados de esa serie es mucho mayor de lo que pensábamos. Y que si de verdad creemos que hay diferencias estadísticamente significativas entre las dos series tendremos que intentar aumentar el número de medidas u observaciones. O admitir lo evidente, que no hay diferencias entre los grupos A y B.
Si publicamos los datos «corregidos» (modificados) entonces daremos a entender a quien los lea que sí hay diferencias estadísticamente significativas entre los dos grupos, cuando en realidad no las hay. Y, por ello, lo más probable es que quien pretenda repetir el experimento sea incapaz de reproducir los mismos resultados, no pueda confirmar que existen esas supuestas diferencias. Y tendremos un problema de reproducibilidad. Ya veis qué sencillo es «manipular» las series de datos para hacer aparecer diferencias significativas donde no las hay. Pues bien, esto que os acabo de demostrar es, tristemente, un comportamiento demasiado habitual y extendido en los laboratorios. E incluso se llegan a buscar las explicaciones más ridículas o peregrinas para «justificar» esta eliminación arbitraria y para calmar nuestra conciencia: «ese dato lo recogí cuando me llamó mi madre al teléfono y estuvo más tiempo que el resto», «ahora recuerdo que ese fue el tubo que se me cayó al suelo», «debí pipetear mal los reactivos que añadí a esa muestra», etc. Por eso los estudiantes y los investigadores al inicio de su formación deben aprender que no podemos eliminar datos a voluntad. Que todos los datos deben ser usados para el análisis. Que debemos aceptar los resultados que tengamos. Y que no podemos forzarlos hasta que nos den el resultado que queríamos obtener con nuestra hipótesis. Este es uno de los males de la ciencia más habituales, un comportamiento inadecuado e inaceptable, una mala práctica, como bien exponen Juan Ignacio Pérez y Joaquín Sevilla en su libro «Los males de la ciencia» (Next Door Publishers, 2022)
Cuidado con escoger las cerezas. Las cerezas no se eligen. Nos las comemos todas.
Hola, me parece muy interesante el ejemplo, aunque pienso que al haber un número de datos bastante bajo, el resultado que aporta el dato «díscolo» modifica mucho la media y la varianza. También es cierto que, a veces, se dan resultados de experimentos como buenos con pocos datos (quizá porque son experimentos complejos y es difícil o costoso tener más). Por otro lado, ¿qué habría que hacer en un caso así? ¿Repetir el experimento o dar por hecho que nos hemos equivocado en la hipótesis? Las excusas que se dan para el dato que no cuadra pueden ser un poco peregrinas, ¡pero hasta podrían ser verdad!
Aprovecho para agradecerte tus siempre interesantes posts en esta web.