
Si hay algún lenguaje universal, usado y entendido por todos los seres vivos y formas de vida que habitamos este planeta prácticamente sin apenas modificaciones este es el código genético. No debemos confundir el código genético con el genoma, que es el que contiene la información genética que se transmite de generación en generación, y que porta las instrucciones para producir todas las proteínas que una determinada especie necesita para sobrevivir. Lo anterior también puede hacerse extensivo a los virus, que no son seres vivos (pues necesitan de la maquinaria celular de los seres vivos a los cuales infectan para completar su ciclo vital y poder replicarse), pero que también usan el mismo código genético para convertir la información genética que transportan en sus genomas, sean estos de ADN o de ARN, en forma de proteínas.
Un equipo de investigadores ha conseguido que una bacteria hable y entienda un idioma distinto, que use un código genético diferente. Ha creado la primera bacteria políglota, capaz de traducir un código genético diferente, creado por los investigadores.
Antes de hablarte de las bacterias políglotas tengo que explicarte o recordarte qué es, cómo se descubrió y cómo funciona el código genético.
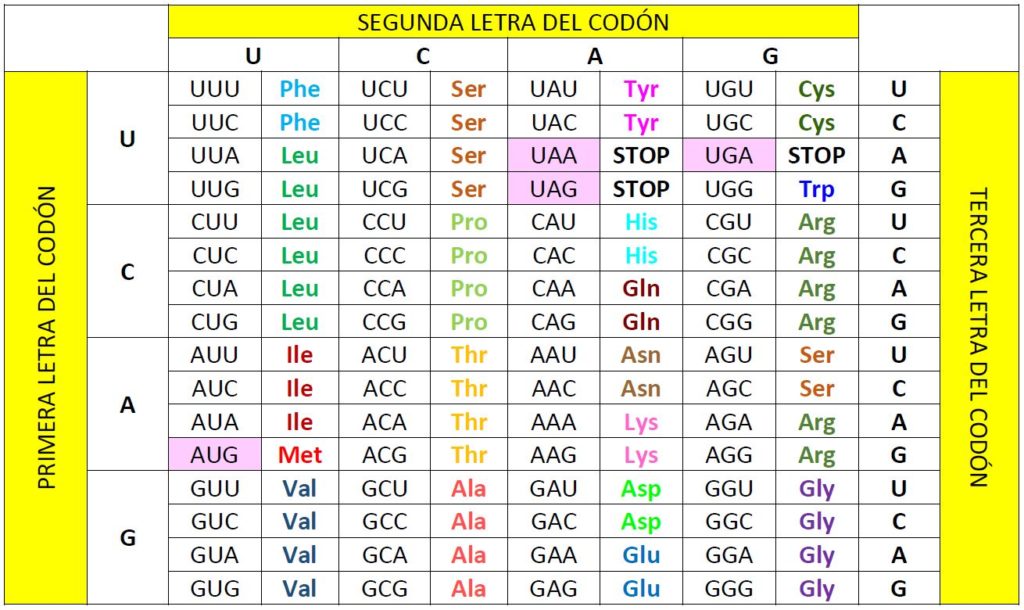
La naturaleza del código genético se empezó a intuir tras el descubrimiento de la estructura del ADN, realizado por Watson y Crick en 1953. En los años siguientes diversos investigadores fueron aportando evidencias y propuestas que llevaron primero a proponer que se trataba un código de tres letras (tripletes), lo cual, teniendo en cuenta que en cada una de las tres posiciones podían estar cualquiera de los cuatro ribonucleótidos [U, A, C, G] daba lugar a 4 elevado a 3 (4x4x4), es decir, 64 combinaciones posibles. Las investigaciones posteriores de Crick, Brenner, Barnett, Watts-Tobin, Niremberg, Matthei, Ochoa, Khorana, Holley, Leder, Epstein, Stenberg y otros investigadores completaron la tabla que aparece al principio de este artículo. Dos premios Nobel reconocieron la importancia de estos descubrimientos. En 1959 Severo Ochoa recibió el Premio Nobel de Fisiología o Medicina, que compartió con Arthur Kornberg, por «sus descubrimientos de los mecanismos de síntesis del ácido ribnonucléico (ARN) y del ácido desoxirribonucléico (ADN)». Nueve años más tarde, en 1968, los investigadores Robert Holley, Har Gobind Khorana y Marshall Nirenberg compartieron el Premio Nobel de Fisiología o Medicina por «su interpretación del código genético y su función en la síntesis de proteínas».
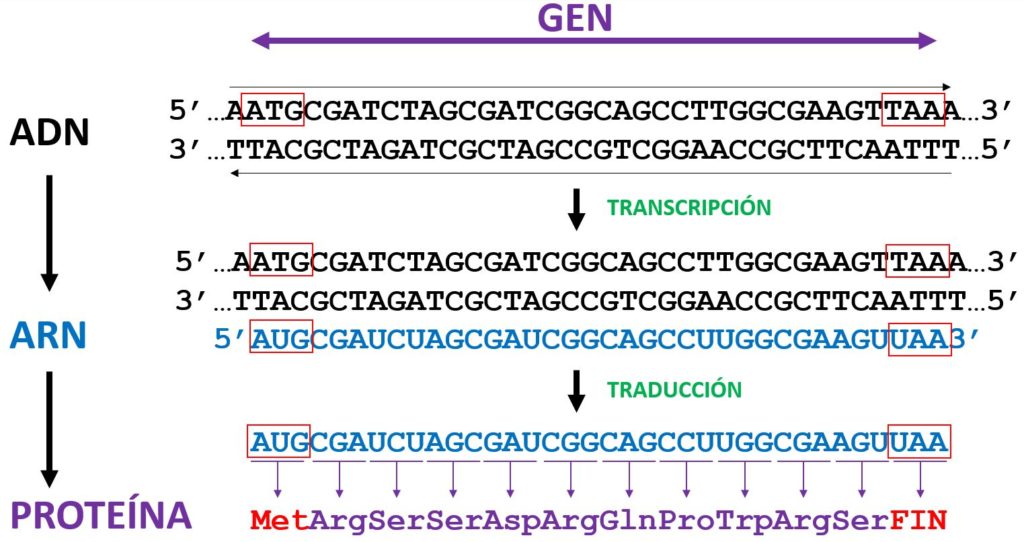
El flujo de información genética que permite transformar el ADN en proteína necesariamente pasa a través de una molécula intermediaria, el ARN. El ADN es una molécula bicatenaria, una doble hélice, constituida generalmente por cuatro tipos de letras (de nucleótidos), asociados cada uno de ellos a una de las cuatro bases nitrogenadas que los forman: la A (adenina), la T (timina), la G (guanina) y la C (citosina). Gracias a Watson y Crick sabemos que la A siempre se aparea con la T, y que la G siempre se aparea con la C. Al ser el ADN una molécula con dos cadenas complementarias y antiparaleas esencialmente cada cadena contiene la misma información. Si conocemos la secuencia de una cadena de ADN implícitamente ya conocemos la secuencia de la cadena complementaria. Compruébalo tú mismo en el esquema anterior.
El ADN para convertirse en proteína debe primero transformarse en ARN. A este proceso de conversión del ADN al ARN lo llamamos transcripción. Si la cadena que contiene la información genética a transcribir es «la de arriba» entonces la maquinaria transcripcional, encargada de la transcripción (la ARN Polimerasa), copiará la cadena de ADN de «abajo» en forma de ARN, de tal manera que la cadena de ARN resultante será una copia exacta de la cadena «de arriba» del ADN, con la salvedad que donde haya una T en el ADN aparecerá una U (que corresponde a la base nitrogenada llamada uracilo) en el ARN. Los cuatro ribonucleótidos que forman el ARN son A, U, G y C.
Finalmente el ARN, que llamamos mensajero, ARNm, será capturado por el ribosoma, que es la fábrica dentro de la célula donde se producen las proteínas, y será decodificado (llamamos a este proceso traducción) siguiendo el código genético de la primera tabla de este artículo. Para empezar a producir la proteína la señal de inicio de síntesis siempre es AUG (que, además, codifica el aminoácido Metionina, Met). Y, partir de ese primer triplete (codón) de AUG iremos contando de tres en tres y cada triplete indicará la adición de un nuevo aminoácido, una nueva unidad constituyente de la proteína, hasta llegar a una señal de terminación, como por ejemplo UAA, que desenganchará la proteína producida del ribosoma, y aquella empezará a realizar su función. Así logramos convertir la información genética residente en un gen del genoma, primero en formato ARN y finalmente en el formato definitivo: la proteína.
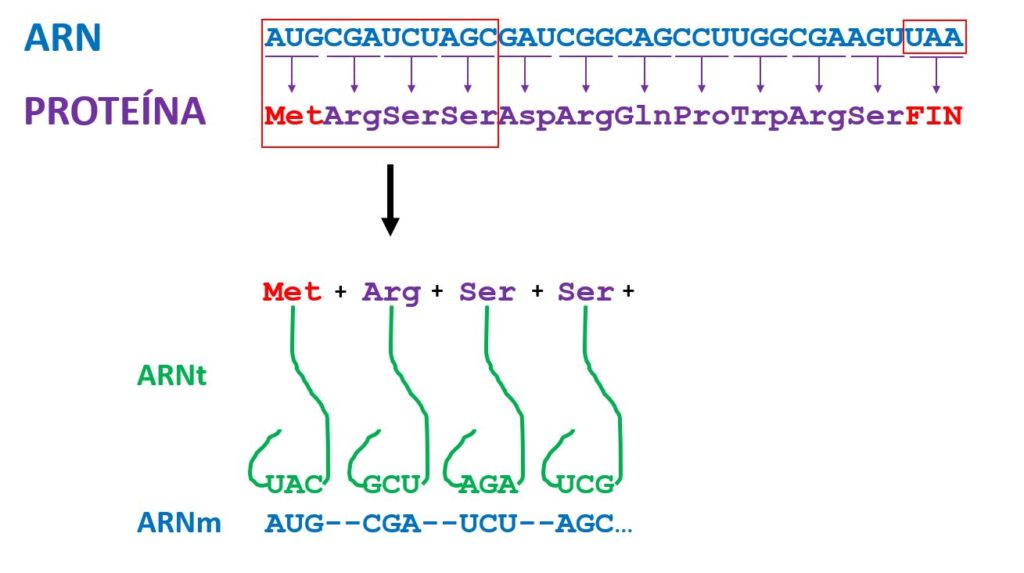
La fase final del flujo de información genética es la que nos permita traducir la información del ARN mensajero (ARNm) en forma de proteína. Esta fase tiene lugar en los ribosomas gracias a la intervención de unas pequeñas moléculas de ARN llamadas ARN de transferencia (ARNt). Estas moléculas portan un extremo que es complementario a la secuencia del codón. Esa secuencia complementaria se llama anticodón. Y en el otro extremo llevan enganchado el aminoácido correspondiente para el que codifican. Y así es como en el ribosoma los ARNt van ubicándose en orden en función de la secuencia de los codones y se va extendiendo, alargando, la proteína hasta llegar a la señal de STOP (FIN) de parada de traducción, que libera la proteína ya sintetizada. Hay 61 tipos de ARNt, uno por cada codón que codifica un aminoácido, exceptuando los tres que codifican señal de STOP.
Te habrás dado cuenta que solamente tenemos 20 aminoácidos para construir proteínas. Sin embargo tenemos 64 tripletes (codones), 64 combinaciones de tres letras para codificarlos. Esto quiere decir que cada aminoácido tendrá más de un código posible. Por ejemplo, en el esquema anterior puedes ver que hay dos aminoácidos consecutivos que son idénticos, Serina (Ser), pero que están codificados por codones distintos: UCU y AGC. Debido a esta característica decimos que el código genético es degenerado, tiene una cierta redundancia, puesto que no hay solamente una solución posible para codificar cada aminoácido, sino varias. Por ejemplo hay seis codones para Ser, Arg y para Leu, cuatro para Thr, Ala, Val y Gly, y dos para los demás, excepto Met y Trp, que solo tienen un codón cada uno.
Además, recuerda que el codón AUG además de servir para codificar Met también sirve de señal de inicio de traducción. Y luego tenemos tres señales de terminación de la traducción: UAA, UAG y UGA que no tienen un ARNt complementario, sino que son reconocidas por los llamados Factores de Liberación (Release Factor, en inglés, RF) que son unas proteínas que reconocen esos codones de terminación y «liberan» a la proteína ya producida del ribosoma. Cada uno de los codones de terminación recibió el nombre de un color: UAA (ocre), UAG (ámbar) y UGA (ópalo). Las bacterias tienen tres factores de liberaración: RF1, RF2 y RF3. RF1 reconoce los codones UAA y UAG. RF2 reconoce los codones UAA y UGA. RF3 ayuda a RF1 y RF2 para liberar la proteína del ribosoma. En eucariotas el factor RF1 se llama eRF1 (de eucariota) y es capaz de reconocer los tres codones de parada. El factor eRF3 funciona como RF3 y no existe RF2.
El que el código genético sea degenerado tiene sus ventajas. Por ejemplo, estos cuatro codones CCU, CCC, CCA y CCG codifican el aminoácido Pro (Prolina). Los cuatro. Si una secuencia de un gen contiene un codón de estos cuatro, por ejemplo, CCC, y cambia (por una mutación) la última letra a CCA, se habrá alterado la secuencia del ADN, y por consiguiente la del ARN, pero no la de la proteína resultante, porque tanto la secuencia original CCC como la nueva mutada CCA codifican para Pro. Y se producirá la misma proteína. Son los llamados cambios sinónimos y esas mutaciones las llamamos silenciosas, porque (en general) no tienen trascendencia ni efecto real en la proteína finalmente producida. Ahora bien, en el mismo ejemplo, si muta la primera letra, que es una C en todos los casos, entonces cambiará el aminoácido codificado y la mutación tendrá consecuencias, que pueden llegar a inhabilitar la función de la proteína parcial o totalmente.
El que el código genético sea degenerado también tiene sus inconvenientes. No todos los seres vivos mantienen la misma proporción de todas las 61 moléculas de ARNt ni usan los codones múltiples con idénticas frecuencias indistintamente, sino que manifiestan preferencias. Hay un uso sesgado de los codones según los organismos, sean sean bacterias, arqueas, levaduras, plantas o animales. Por lo tanto un gen de bacterias se traducirá de forma subóptima en una célula humana, a no ser que editemos y cambiemos los codones para convertirlos en los que preferentemente usan las células humanas. A este proceso se le llama «humanizar» el gen bacteriano. Veamos un ejemplo.

Hecha la introducción y comentados los aspectos más relevantes del código genético ahora ya puedo pasar a hablarte con algo más de detalle de las bacterias políglotas. Hace un par de años, en 2019, un grupo de investigadores del prestigioso Laboratorio de Biología Molecular LMB-MRC de la Universidad de Cambridge, en el Reino Unido, liderados por Jason W. Chin, creó una nueva cepa de bacterias Escherichia coli con un genoma sintético de ~4 Mb (4 millones de pares de bases) en el que cambiaron 18,214 codones de su ADN para reducir la complejidad de los 64 codones iniciales a 61, es decir eliminado tres de ellos. De los 61 restantes, 59 eran los que se usaban para codificar los 20 aminoacidos necesarios y los dos adicionales eran los necesarios para terminar la traducción, las señales de parada.

En este primer y sorprendente trabajo estos investigadores decidieron eliminar dos de los codones de los seis que codifican el aminoácido Serina (Ser) TCG y TCA (en el ADN, en el ARN serían UCG y UCA) y los substituyeron por otros que también codificaban Ser, los codones AGC y AGT (en el ADN, en el ARN serían AGC y AGU) (puedes consultar la tabla del principio de este artículo para verificarlo). Adicionalmente transformaron uno de los codones de terminación TAG (en el ADN, en el ARN sería UAG) y lo cambiaron por TAA (en el ADN, en al ARN sería UAA). Los codones UAG y UAA son reconocidos por el factor de liberación RF1, mientras que el factor RF2 reconoce también a UAA y a UGA. Dado que los investigadores eliminaron todos los UAG y los convirtieron a UAA, en la bacteria resultante solo quedaron los codones de terminación UAA y UGA, que son reconocidos por el factor RF2 y entonces podía eliminarse igualmente el factor RF1. Esto lo hicieron sistemáticamente en todo el genoma de la bacteria y tuvieron que cambiar 18,214 codones.
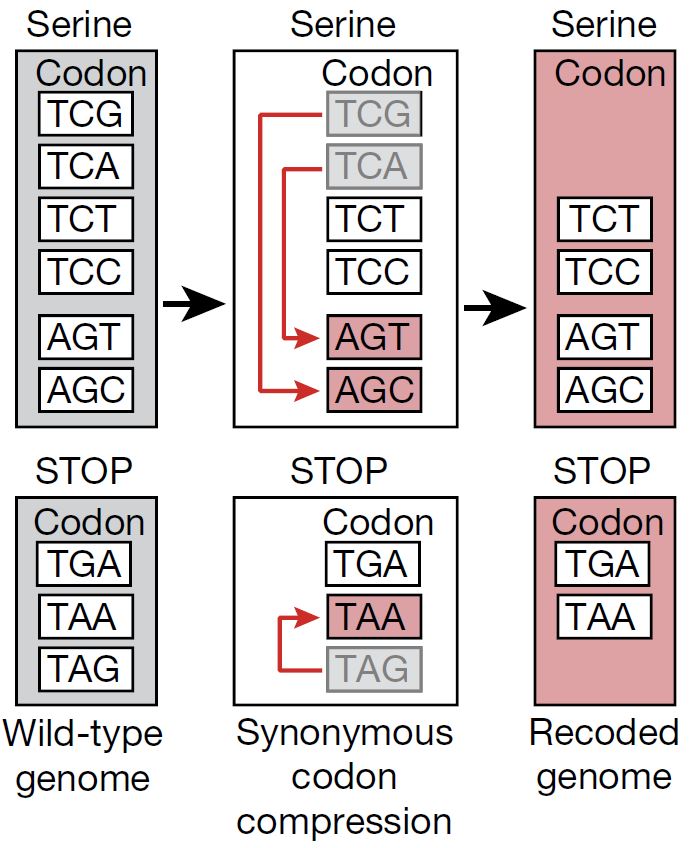
Los investigadores, una vez substituidos todos los codones afectados en más de 18,000 sitios del genoma quisieron comprobar que tanto el ARN de transferencia (ARNt) específico de los codones de Serina eliminados como el gen que codifica el factor de liberación 1 (RF1) podían ser eliminados, dado que los ARNt restantes que portan Serina y el factor RF2 serían suficientes para seguir incorporando el aminoácido Ser en la síntesis de proteínas cuando correspondiera, y que la terminación de la síntesis la llevaría ahora a cabo el factor RF2, siendo el factor RF1 redundante. Y por ello prepararon la cepa final resultante de todas estas modificaciones, a la que llamaron Escherichia coli Syn61.
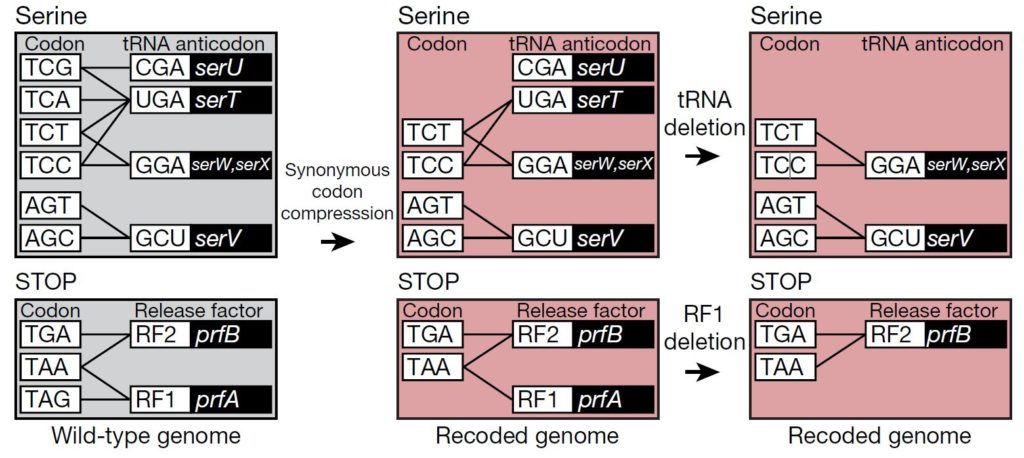
La bacteria Escherichia coli Syn61 puede prescindir del gen ARNt que porta el anticodon TCG de Ser (serU) y del gen que codifica el factor de liberación RF1 (prfA), que ya no es necesario, puesto que RF2 se basta y se sobra para reconocer los dos codones de terminación que le quedan a esta bacteria con el genoma sintético modificado. De alguna manera estos investigadores crearon una bacteria que hablaba un dialecto del código genético, uno en el que habían desaparecido tres palabras. Sin embargo la bacteria seguía creciendo normalmente, solamente un poco más lentamente que la bacteria original de la que derivaba. Este primer experimento, sorprendente, demostró que la vida tal y como la conocemos no necesita los 64 codones del código genético. Se puede crear y mantener vida, un ser vivo como esta bacteria, con solamente 61 codones. Se puede prescindir de tres codones. Y la vida continua.
Pero los investigadores no se detuvieron aquí, y siguieron investigando.

Hace unos pocos días se acaba de publicar el siguiente estudio del mismo equipo investigador (Robertson et al. Science, 2021) donde estos científicos exploran las características de esta nueva cepa de bacterias Escherichia coli Syn61. Se había hipotetizado que si se eliminaran alguno de los ARN de transferencia (ARNt) en una bacteria esta se convertiría en resistente a la infección por virus, dado que el genoma de los virus seguiría teniendo en sus genes codones para los cuales ya no habría el anti-codón correspondiente, y la síntesis de proteína de bloquearía y detendría en esa posición. Sin posibilidad de continuar la producción de proteínas virales el virus no podría replicarse ni completar su ciclo de infección en las células. De la misma manera, si se eliminara uno de los factores de liberación, de terminación de la síntesis, responsable de reconocer uno de los codones de terminación, pasaría lo mismo. Se bloquearía y detendría la síntesis de la proteína que no podría liberarse del ribosoma. Y, en efecto esto es lo que encontraron los investigadores. Esta bacteria de genoma sintético y modificado era completamente resistente a muchos virus que habitualmente infectarían a Escherichia coli, pero que ahora eran incapaces de infectar a la cepa Syn61.
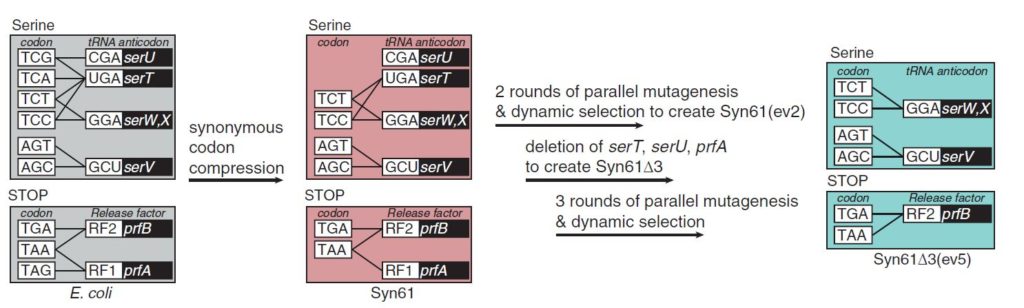
La cepa que construyeron estos investigadores, llamada Syn61Δ3, portaba tres genes inactivados. Dos de ellos codificaban para los ARNt de Serina con anti-codones complementarios a los codones ya eliminados del genoma (serU y serT), y el tercer gen (prfA) codificaba el factor de liberación RF1, que tampoco era necesario.
Una vez comprobada la resistencia de esta bacteria a la infección por cualquier tipo de virus que habitualmente infectaría estas bacterias, los investigadores decidieron enseñarle a esta bacteria otro idioma. Hacerla políglota, que usara otro código genético. La reducción de 64 a 61 codones dejaba tres codones libres (UCG, UCA, UAG) que ahora podían ser usados para codificar otros amino ácidos no canónicos, y así «enseñar» a la nueva bacteria un nuevo idioma, que permitiera la síntesis de proteínas complejas (y además libre de infecciones por cualquier virus, contra los que sería totalmente inmune), en las que, además de los 20 aminoacidos naturales también pudieran insertarse otros distintos, con propiedades diferentes, potencialmente beneficiosas para la propia célula o para su uso como herramienta o biorreactor biotecnológico.
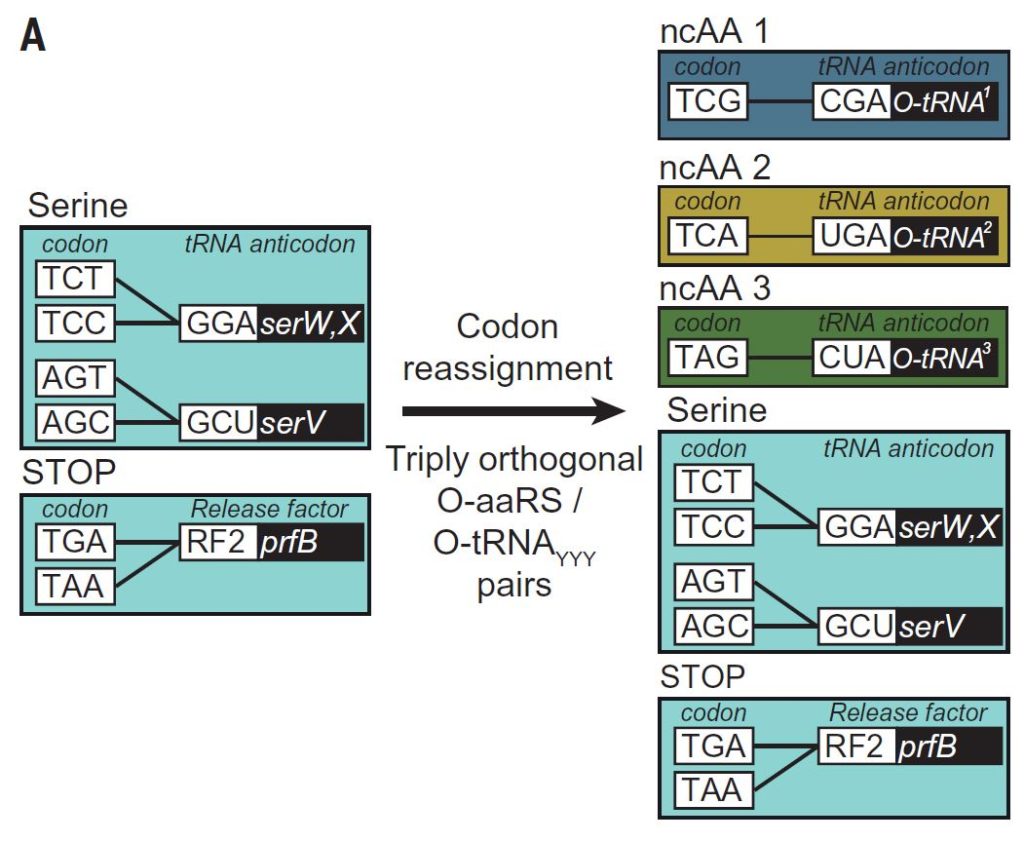
En este estudio, recientemente publicado, los investigadores generaron tres nuevos ARNt con anti-codones complementarios a los tres codones eliminados del genoma de la bacteria (UCG, UCA, UAG) y asociaron cada uno de ellos a un aminoácido no canónico diferente, tres moléculas químicas similares a los aminoácidos naturales abreviadas como Allock, Bock y CbzK. Y ahora, incorporando de nuevo estos codones en las secuencias de varios genes de la bacteria y aportando estos nuevos ARNt demostraron que era posible que la bacteria «leyera» estos codones de nuevo, que se le habían eliminado antes, y que los interpretará de acuerdo al «nuevo idioma» que había aprendido, al nuevo código genético que portaba. Las bacterias disciplinadamente produjeron las nuevas proteínas que tenían en las posiciones previstas el aminoácido no canónico correspondiente que habían codificado.
Este experimento abre la posibilidad a desarrollar bacterias que produzcan compuestos o proteínas hasta ahora imposibles de sintetizar in vivo, quizás nuevos antibióticos, nuevos compuestos antitumorales, nuevos medicamentos, simplemente combinando nuevas estructuras químicas, nuevos aminoácidos no canónicos y asociándolos a ARNt que sean complementarios a los codones eliminados de esta cepa de bacterias. La imaginación de los químicos y los microbiólogos se me antoja de nuevo como el único límite para el descubrimiento de nuevos fármacos con nuevas propiedades. Ha nacido una nueva era para la biotecnología microbiana.
Estos resultados son todavía más sorprendentes y dan un vuelco a la universalidad del código genético. Ahora es posible enseñar a bacterias a usar otros códigos. Podemos tener bacterias políglotas, que hablen diferentes idiomas. En una misma especie (p.ej. Escherichia coli) pueden coexistir diferentes cepas capaces de interpretar diversos códigos, aunque cada cepa de bacterias modificada solamente hablará uno, el que corresponda al código genético que tenga programado.
«Cosas veredes, amigo Sancho…«
Gran artículo como siempre Lluis! La única duda que me ha surgido es por qué al desarrollar cepas bacterianas que posean códigos genéticos modificados se podrían fabricar proteínas que hasta ahora no era posible: ¿es debido a que al liberar codones y hacer que se descodifiquen como aminoácidos no canónicos las bacterias podrían sintetizar nuevas proteínas formadas de esos aminoácidos «especiales»? Muchas gracias por tu trabajo y un saludo.
Gracias Oliver, exactamente es por eso. Al liberar codones y asociarlos a (ARNt portadores de) aminoácidos no convencionales se pueden generar bacterias que produzcan proteínas con esos aminoácidos no canónicos en posiciones predefinidas, de acuerdo con la secuencia, que antes no se hubieran podido generar. Saludos.
Muy instructivo. Desde luego, como apunta el artículo, bien pudiera tratarse de la antesala de una (bio)tecnología revolucionaria.
Está abriéndose cada vez más un abanico de posibilidades disruptivas en este campo que lo podrán cambiar todo.
De manera paralela, seguramente el peso de la responsabilidad irá aumentando sobre nuestros hombros y tendremos que mirarnos delante del espejo, cada vez con mayor frecuencia, para preguntarnos hasta dónde querríamos llegar…
No parece un mal ejercicio: puede que nos haga, finalmente, más conscientes de todo lo que nos rodea y de nosotros mismos.
Asombroso. Solo espero que todos estos magníficos avances se utilicen con el buen criterio que Sancho Panza demostró en el gobierno de la insula barataria.
Gracias profesor